🌟MiniMax-M1: открытя reasoning‑LLM с контекстом 1M
MiniMax-M1 — первая в мире open-weight гибридная reasoning‑LLM c 1M контекстом (8× DeepSeek R1) и гибридной архитектурой MoE + lightning attention. • 456 млрд параметров (45,9 млрд активируются на токен), сверхэффективная генерация — 25% FLOPs DeepSeek R1 на 100K токенов • Обучение через RL с новым алгоритмом CISPO, решающим реальные задачи от математики до кодинга • На обучение было потрачено $534K, две версии — 40K/80K “thinking budget” • Обходит DeepSeek R1 и Qwen3-235B на бенчмарках по математике и кодингу, • Топ результат на задачах для software engineering и reasoning
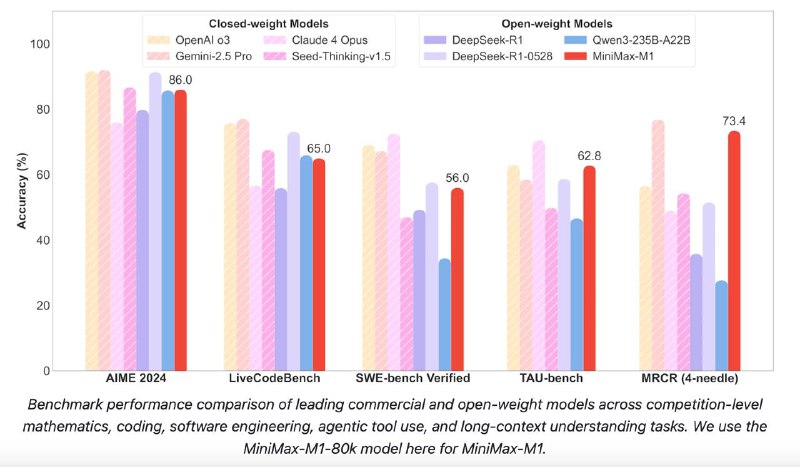
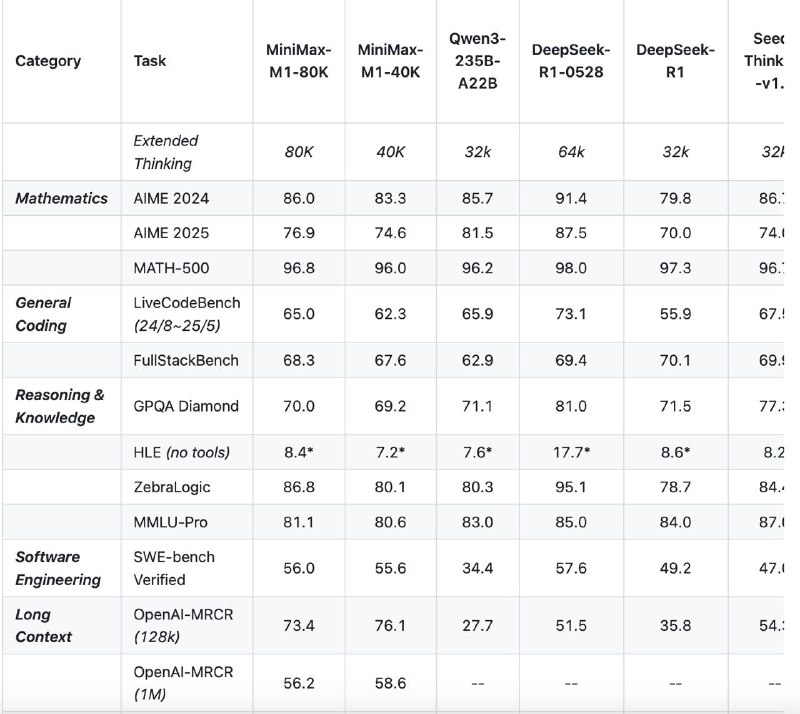
Бенчмарки: AIME 2024: 86.0 (M1-80K) vs 85.7 (Qwen3) vs 79.8 (DeepSeek R1)
🌟MiniMax-M1: открытя reasoning‑LLM с контекстом 1M
MiniMax-M1 — первая в мире open-weight гибридная reasoning‑LLM c 1M контекстом (8× DeepSeek R1) и гибридной архитектурой MoE + lightning attention. • 456 млрд параметров (45,9 млрд активируются на токен), сверхэффективная генерация — 25% FLOPs DeepSeek R1 на 100K токенов • Обучение через RL с новым алгоритмом CISPO, решающим реальные задачи от математики до кодинга • На обучение было потрачено $534K, две версии — 40K/80K “thinking budget” • Обходит DeepSeek R1 и Qwen3-235B на бенчмарках по математике и кодингу, • Топ результат на задачах для software engineering и reasoning
Бенчмарки: AIME 2024: 86.0 (M1-80K) vs 85.7 (Qwen3) vs 79.8 (DeepSeek R1)